Backup Methods
Veeam Backup & Replication stores backups on disk using a simple, self-contained file based approach. However, there are several methods to create and store those files on the file system. This section will provide an overview of these methods, their pros and cons, as well as recommendations on use cases for each one.
Backup mode directly influences disk I/O on both production storage and backup repository, and backups size; for these reasons it is recommended to carefully review capabilities of the destination storage when selecting one. Take a look at Deduplication Appliances section of this guide for important details on using dedicated deduplicating hardware appliances for storing backups.
For a graphical representation of the mentioned backup modes in this section, please see Veeam KB1799.
As a generic overview for I/O impact of the backup modes, please see this table:
| Method | I/O impact on destination storage |
|---|---|
| Forward incremental | 1x write I/O for incremental backup size |
| Forward incremental, active full | 1x write I/O for total full backup size |
| Forward incremental, transform | 2x I/O (1x read, 1x write) for incremental backup size |
| Forward incremental, synthetic full | 2x I/O (1x read, 1x write) for entire backup chain |
| Reversed incremental | 3x I/O (1x read, 2x write) for incremental backup size |
| Synthetic full with transform to rollbacks | 4x I/O (2x read, 2x write) for entire backup chain |
While changing backup mode is one way of reducing amount of I/O on backup repository it is also possible to leverage features of the filesystem to avoid extra I/O. Currently Veeam Backup and Replication supports advanced features of one filesystem, Microsoft ReFS 3.1 (available in Windows Server 2016), to completely eliminate unnecessary read/write operations in certain configurations. For more details refer to the corresponding section of this guide. [ReFS chapter is working in progress]
Forward Incremental
The forward incremental backup method is the simplest and easiest to understand; it generally works well with all storage devices although it requires more storage space than other backup methods due to the fact that it requires the creation of periodic full backups (either using active or synthetic backups), typically scheduled weekly. This is necessary because the incremental backups are dependent on the initial full backup; thus, older full backups cannot be removed from the retention chain until a newer backup chain is created. When a new full backup is created, a new chain is started, and the old backups can be removed once the new chain meets the retention requirements.
Active Full Backups
The first time a job is run it always performs an active full backup. During this process the VM is read in full (with the exception of blank blocks and swap areas), and VM data is stored (typically compressed and deduplicated) into a full backup file (.VBK).
Each time an active full is performed (either on schedule or by manually triggering the Active Full command), a new .VBK file is created by reading all data from the production storage. Following incremental backups are stored in incremental backup files (.VIB).
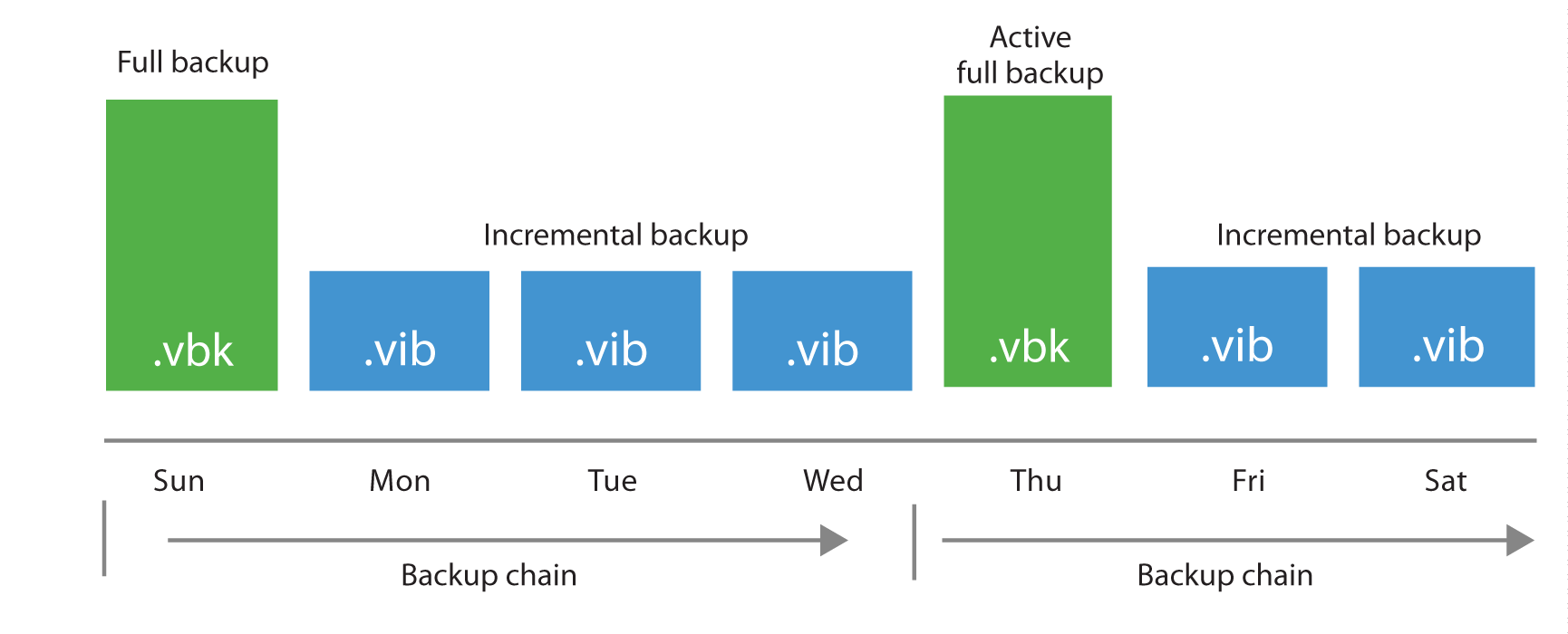
When performing active full backups, all blocks are re-read from the source storage.
I/O Impact of Active Full
When creating an active full, the I/O pattern on the backup storage is mainly sequential writes, which generally provides good performance for most storage solutions. However, all the data (not just the changes) has to be copied from the production storage, and this will increase the duration of the backup activity and the time a VM snapshot remains open (see also the "Impact of Snapshot Operations" section of this guide). The snapshot lifetime can be reduced by leveraging Backup from Storage Snapshots.
When to use
Forward incremental backup provides good performance with almost any storage and the highest level of backup chain consistency since each new chain is populated by re-reading VM source data. Incremental backups are still processed using Changed Block Tracking (CBT) thus data reduction is still possible. Active Full can be used in any case where plenty of repository space is available, the backup window allows enough time and network bandwidth is sufficient to support reading the source data in full.
| Use | Don't Use |
|---|---|
| Recommended for deduplication appliances that use SMB or NFS protocols. | When backup window does not allow enough time for re-reading all of the source VM data. |
| On storage systems that use software or non-caching RAID hardware such as many low-end NAS devices. | For large or performance sensitive VMs where re-reading the data can have a negative impact on the VMs performance. |
Synthetic Full
Synthetic full reads the data already stored in the most recent backup chain (full and its dependent incrementals) to create a new full backup directly into the destination storage.
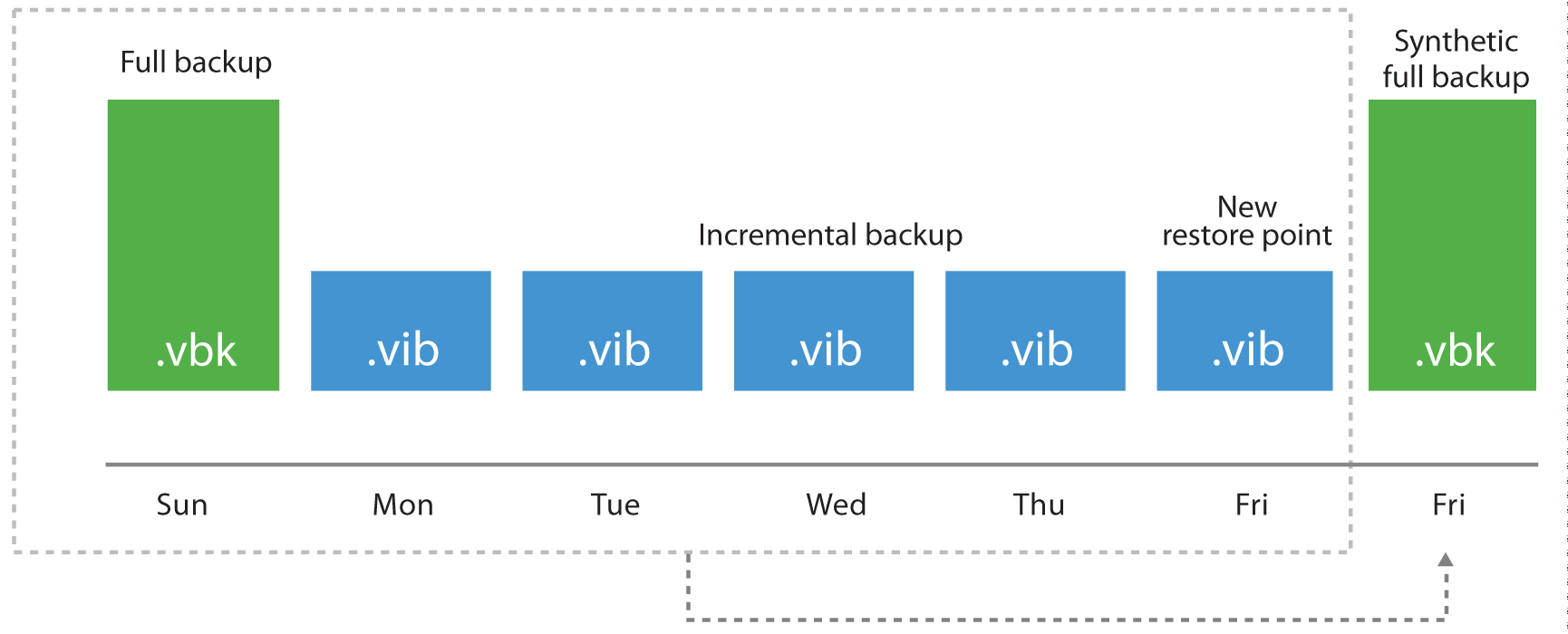
If a synthetic full is scheduled, when the job runs, it first creates a normal incremental backup to collect the most recent changes.
After the job completes the incremental backup, the synthetic full generation is started. It reads the most recent version of each block for every VM in the job from the backup chain, and writes those blocks into a new VBK file. This is how a new full backup is "synthetically" created.
I/O Impact of Synthetic Full
Synthetic full I/O patterns need to be split into two different operation: the creation of the additional incremental is exactly like any other incremental job. However, the synthetic creation of the full backup is an I/O intensive process, all in charge of the Veeam repository. Since the process reads individual blocks from the various files in the chain and writes those blocks to the full backup file, the I/O pattern is roughly 50%-50% read/write mix. The processing speed is limited by the IOPS and latency capabilities of the repository storage, so it may take a significant amount of time. However, there is no impact on the source storage or production networks during this time as I/O occurs only inside the repository.
NOTE: if an SMB share type of repository is used, the Veeam repository role is executed in the Gateway Server there is going to be network traffic between the gateway server itself and the SMB share.
Recommendations on Usage
Due to the way synthetic full works, having many smaller backups jobs with fewer VMs will allow for faster synthetic full operations. Keep this in mind when setting up jobs that will use this method or choose to use Per VM Backup Files.
| Use | Don’t Use |
|---|---|
| When repository storage uses fast disks with caching RAID controllers and large stripes. | Small NAS boxes with limited spindles that depend on software RAID. |
| Deduplication appliances that support offloading synthetic operations (DataDomain, StoreOnce and ExaGrid) | Deduplication appliances that use SMB or NFS protocols. |
Forever Forward Incremental
Forever forward incremental method creates one full backup file (VBK) on the first execution, and then only incremental backups (VIBs) are created. This method allows backup space to be utilized efficiently, as there is only a single full backup on disk, and when the desired retention is reached a merge process is initiated. It reads the oldest incremental backup and writes its content inside the full file, virtually moving it forward in the timeline where the merged incremental was before.
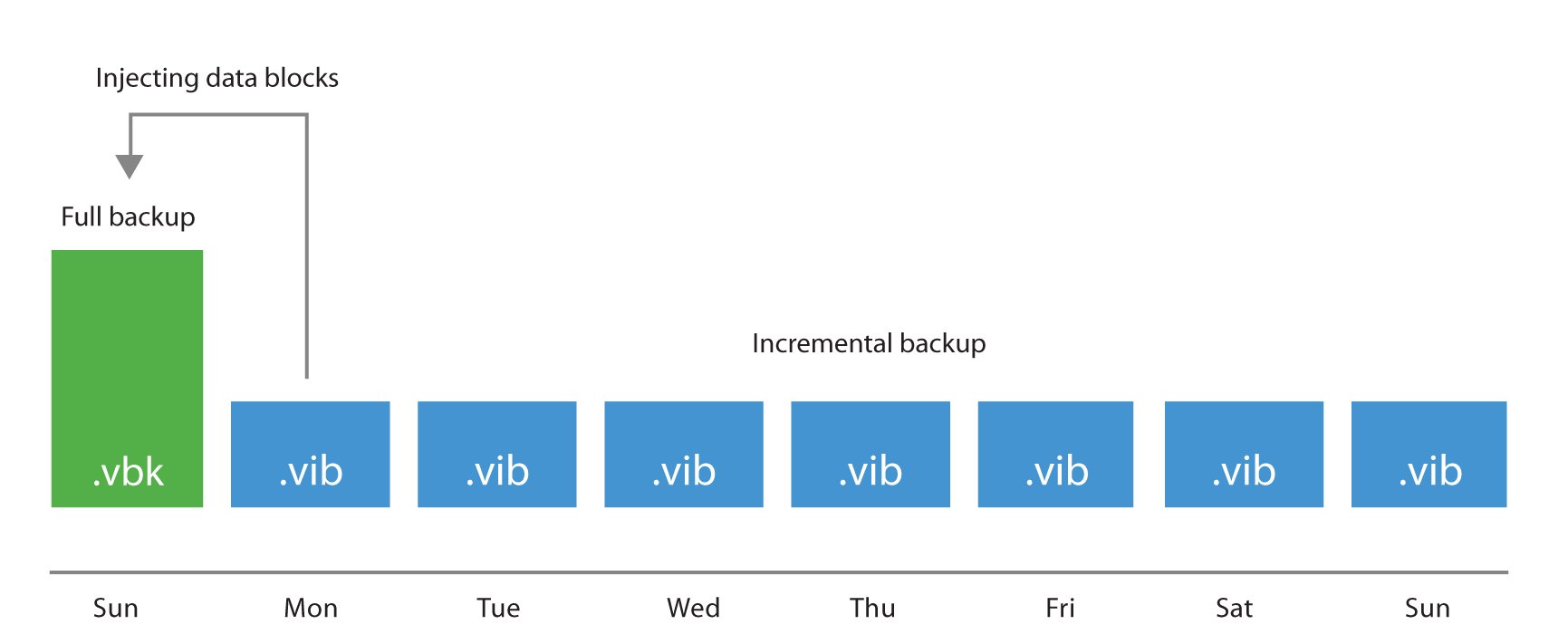
I/O Impact of Merge Process
The merging process is performed at the end of the backup job once the retention for the job has been reached. This process will read the blocks from the oldest incremental backup (VIB file) and write those blocks into the VBK file; the I/O pattern is a 50%-50% read-write mix on the target storage. The time required to perform the merge depends on the size of the incremental data and the random I/O performance of the underlying storage.
Recommendations on Usage
The primary advantage of using forever forward incremental backup method is space savings. However, the tradeoff is the required resources for the merge process. The merge process may take a considerable amount of time, depending on the amount of incremental changes that the job has to process. The advantage is that the merge process impacts only the target storage.
Like with synthetic full, it is recommended to have many smaller jobs with a limited number of VMs, as this can significantly increase the performance of synthetic merge process. Very large jobs can experience significant increase in time due to extra metadata processing. This may be remediated by combining forever forward incremental mode with per VM backup files.
| Use | Don’t Use |
|---|---|
| Repositories with good performance | Smaller backup repositories or NAS devices with limited spindles and cache |
| Ideal for VMs with low change rate | Jobs with significant change rate may take a long time to merge |
Reverse Incremental
As every other backup method, during its first run reverse incremental backup creates a full backup file (VBK). All subsequent backups are incremental, that is, only changed data blocks are copied. During the incremental backup, updated blocks are written directly into the full backup file, while replaced blocks are taken out and written into a rollback file (.VRB).
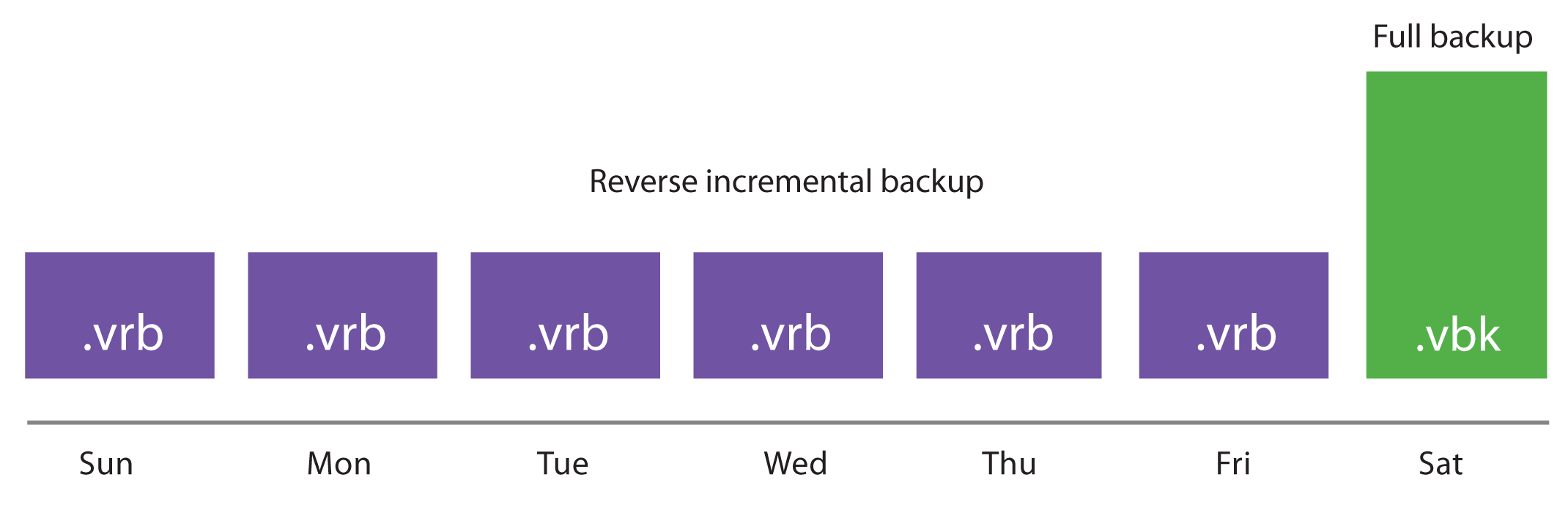
This method provides space-efficient backup, as there is only one full backup to store. It also facilitates retention, since removing old restore points is simply a matter of deleting old VRB files.
The disadvantage is that creation of rollback files occurs during the backup process itself, which results in higher I/O load on the target storage and can slow down the backup process.
Also, over time the in-place injection of new blocks into the full file causes fragmentation of the VBK file. This can be partially fixed by using compact operations.
I/O Impact of Reverse Incremental
During the backup process new blocks are read from the source VM and are written directly to the VBK file. If this block replaces an existing older block, this old block is read from the VBK and then written to the VRB file, and replaced by the new one into the VBK file itself. This means that reverse incremental backups creates a 33%-66% read-write IO pattern on the target storage during the backup process itself. This I/O typically becomes the limiting factor for backup performance of the job. As the rollback is created during the backup process itself, backup throughput can be limited by target storage. This slower performance can lead to VM snapshots staying open for a longer time.
This can be especially noticeable for VMs with a high change rate, or when running multiple concurrent jobs.
Recommendations on Usage
| Use | Don’t Use |
|---|---|
| When repository storage uses fast disk with caching RAID controllers and large stripe sizes | Small NAS boxes with limited I/O performance |
| VMs with low change rate | Deduplication appliances due to random I/O pattern |
| High change rate VMs, as VM snapshot may be open for a long time |