Scale Out Backup Repository
Veeam Scale-out Backup Repository is a logical entity made of multiple “simple” repositories, grouped together into a single abstracted object, that can be used as a target for any backup and backup copy job operation.
Scale-out Backup Repository is an extremely easy way for both medium and large customers to extend repositories when they run out of space. Instead of facing the long and cumbersome relocation of backup chains, users will be able to add a new extent (that is any of the “simple” backup repositories supported by Veeam Backup & Replication) to the existing Scale-out Repository — or group multiple repositories to create a new one.
The only requirement is the ownership of a proper license, and that at least two simple repositories have been added to Veeam Backup & Replication already. As per default settings, it is recommended to enable "per VM backup files" on the Scale-out Backup Repository for optimal balancing of disk usage.
NOTE: the default backup repository created during the installation cannot be used in a Scale-out Backup Repository as long as it’s the target of Configuration Backup, as this type of job is not supported by Scale-out Backup Repository. If the default repository needs to be added to a Scale-out Backup Repository, consider first to change the target of Configuration Backup.
For additional technical information, the online documentation is available here : https://helpcenter.veeam.com/backup/vsphere/backup_repository_sobr.html.
File placement policies
Scale-out Backup Repository has two different options for file placement.
Data Locality
This is the default policy, and it works by placing all the dependent files of a backup chain into the same extent. Every extent grouped with this policy has the same chances of receiving a backup chain as the algorithm treats them equally, and the major parameter for the initial placement is the free space value.
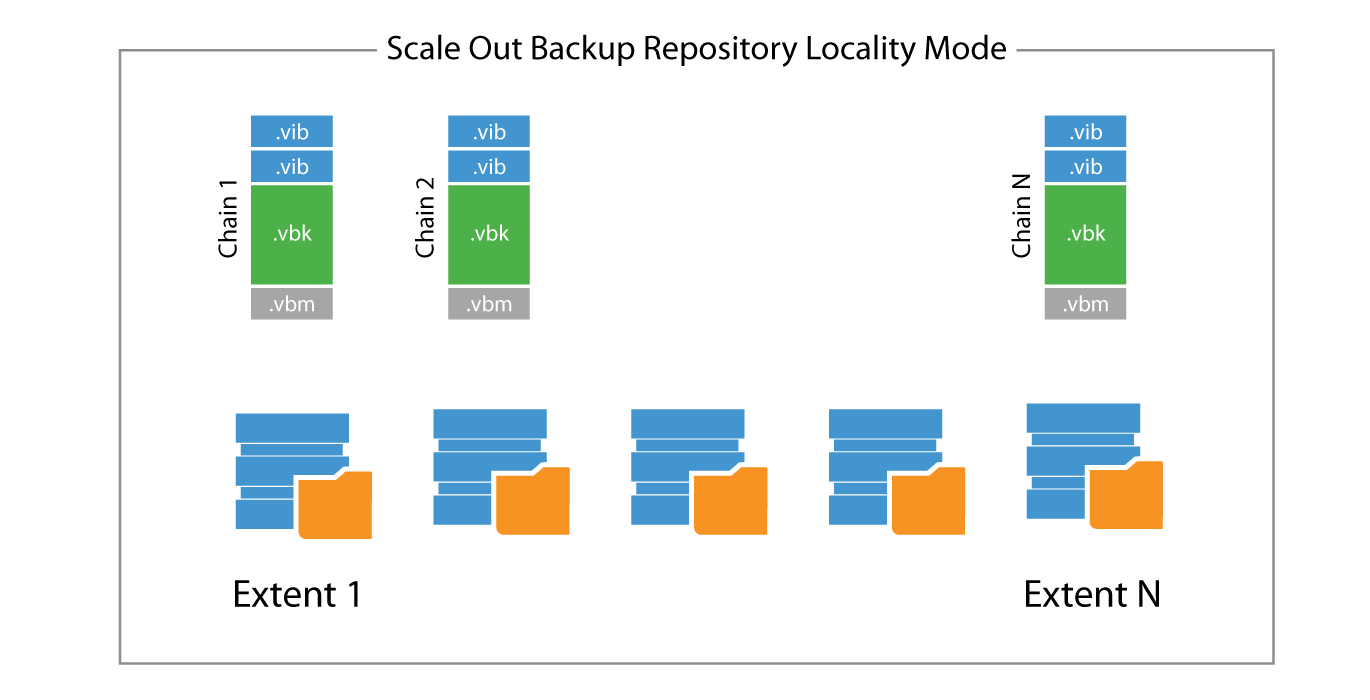
The failure domain is a single extent, as the loss of a given extent impacts only the backup chains stored into that extent. Policy can be violated by Veeam itself if, for example, one of the extents has no free space left, and the additional incremental is stored in a different extent. This because the priority is always to complete a backup or backup copy.
Performance
Performance policy places dependent incremental backup files on a different extent from the corresponding fulls. In order to choose which extent will hold the different files when using the performance policy, for each extent users are able to assign it a “role”.
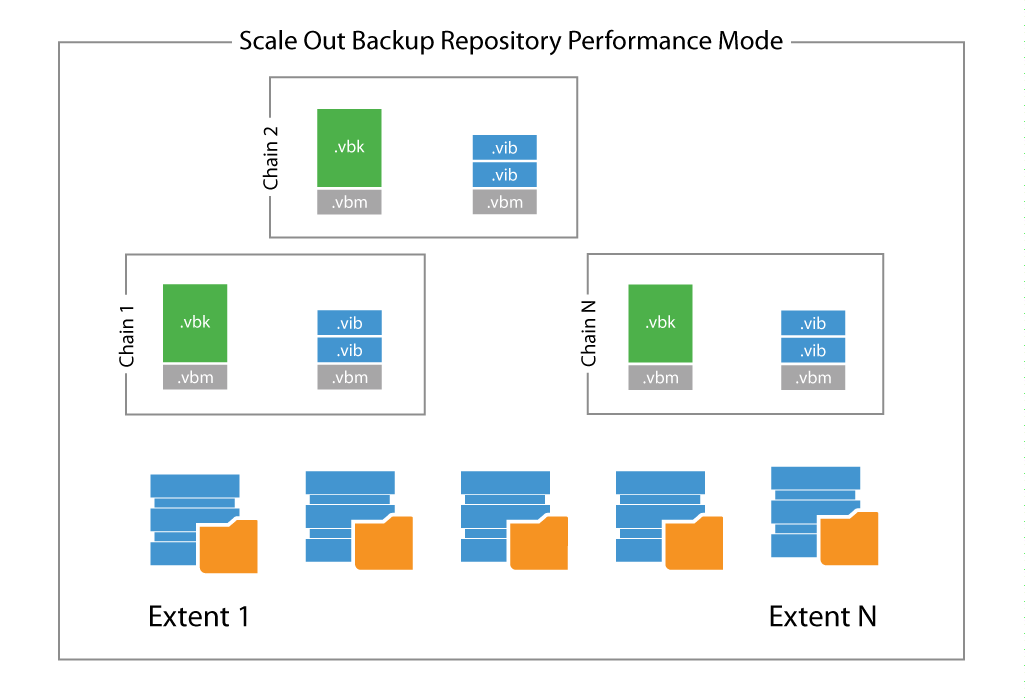
Important: When using integrated deduplication devices, virtual synthetic operations may not work, if the full and incremental backup files are placed on separate extents. Please use Data Locality mode instead.
Users can configure each repository of the group to accept full backups, incremental backups or both. As soon as a new backup chain is stored into a performance Scale-out Backup Repository, the different files are place in accordance to the policy itself.
Note: in order to leverage the performance policy correctly users need to use at least two different repositories. Even if it’s possible to assign both roles to the same repository, this configuration makes little sense and the best results can be obtained by splitting full backup files and incremental backup files over different physical extents.
Performance policy increases the failure domain — a backup chain is split over at least two repositories, thus the loss of one of the two corrupts the entire backup chain. This is a consideration that Veeam architects need to evaluate carefully. There is a trade-off between the increased performance guaranteed by the performance placement policy, and the increased failure domain.
Scale-out Backup repository and network considerations
Scale-out Backup Repository is, as the name implies, a scale out arhitecture, based on multiple datamovers, with a notion of master and slave repository datamovers.
During backups, the master datamover is always started where the write is happening. During restore, the master is always started where the VBK is located, as most blocks are likely retrieved from this location.
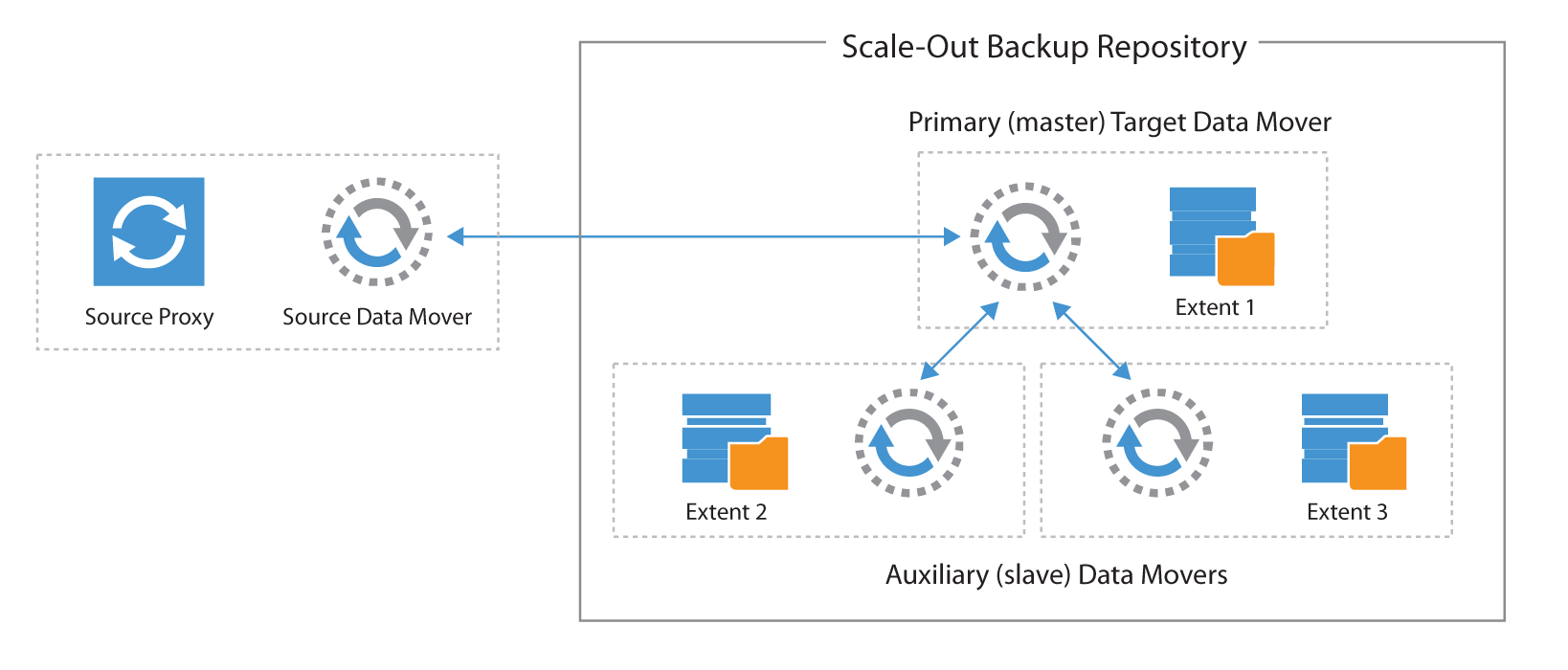
A master datamover is the only repository datamover receiving data from a source datamover (a proxy in a backup job or a source repository in a backup copy job). A master datamover is able to communicate if needed with other slave datamovers to retrieve their data.
As in any scale-out solution, careful design should be applied to the network, as communications between the different data movers may increase network consumption, regardless the policy in use or the specific design of the scale-out architecture. When using Scale-out Backup Repository, 10 Gb networks are always recommended.